I’ve seen a lot of CSS style guides online, but I always found them talking more about how to choose a selector name and how to structure your components rather than talking about CSS itself. I do a lot of code review at Robusta and reviewing CSS is something I enjoy doing. I tried to collect the notes that I found myself leaving for my colleagues and decided to start this opinionated style guide.
Source file basics
File name
File names must be all lowercase and may include dashes (-), but no additional punctuation. Follow the convention that your project uses. Filenames’ extension must be css or other preprocessor extensions (sass, less … etc).
File encoding: UTF-8
Source files are encoded in UTF-8. Encoding should be specified in the file header using the @charset directive. This should be added to the root file that include all the styles or to every other file that isn’t included in the root file.
@charset "UTF-8";
Structure
We follow the ITCSS methodology for writing CSS. ITCSS require the following directory structure:
settings: settings will be used across the project like color variables, the fonts that will be used … etc.tools: globally used mixins and functions. It’s important not to output any CSS in the first 2 layers.generic: reset and/or normalize styles, box-sizing definition, etc. This is the first layer which generates actual CSS.elements: styling for bare HTML elements (like H1, A, etc.). These come with default styling from the browser so we can redefine them here.objects: class-based selectors which define undecorated design patterns, for example media object known from OOCSS, the grid …etc.components: specific UI components. This is where majority of our work takes place and our UI components are often composed of Objects and Components.utilities: utilities and helper classes with ability to override anything which goes before in the triangle, eg. hide helper class.
We might need to include vendor styles (CSS specific to a UI library we are using), these ones are set between objects and components layers.
Each group of declarations should be written in a sepearate file. For example, to define the project’s box-model, we would write a file named box-model.css in the generic layer.
Note: One of the common mistakes developers do is that they put some rules in the wrong layer. For example, we might want to define the font that will be used in the website. Font is an inherited value so we usually write it using a body selector. Developers would create a file in the elements layer and put the font declaration there. This is wrong because that file is specific to the style we need to define on the body (like background-color, height … etc). Setting the used font should be done in the generic layer by creating a file called typography.css and putting the font declaration there.
@charset "UTF-8";
/* Settings – used with preprocessors and contain font, colors definitions, etc. */
@import "settings/fonts.css";
@import "settings/colors.css";
/* Tools – globally used mixins and functions. It’s important not to output any CSS in the first 2 layers. */
/* Functions */
/* Mixins */
/* Generic – reset and/or normalize styles, box-sizing definition, etc. This is the first layer which generates actual CSS. */
@import "generic/box-model.css";
@import "generic/typography.css";
/* Elements – styling for bare HTML elements (like H1, A, etc.). These come with default styling from the browser so we can redefine them here. */
@import "elements/anchor.css";
@import "elements/img.css";
@import "elements/body.css";
/* Objects – class-based selectors which define undecorated design patterns, for example media object known from OOCSS */
@import "objects/grid.css";
@import "objects/media.css";
@import "objects/pagination.css";
/* Vendor - These are resolved from node_modules by the postprocessors automatically */
@import "swiper/swiper-bundle.css";
@import "swiper/components/effect-fade/effect-fade.scss";
/* Components – specific UI components. This is where majority of our work takes place and our UI components are often composed of Objects and Components */
@import "components/header.css";
@import "components/footer.css";
/* Utilities – utilities and helper classes with ability to override anything which goes before in the triangle, eg. hide helper class */
@import "utilities/text-align.css";
@import "utilities/screen-reader.css";
@import "utilities/display.css";
Naming
We follow the BEM naming convention.
Braces
Braces follow the Kernighan and Ritchie style as follow:
- No line break before the opening brace.
- Line break after the opening brace.
- Line break before the closing brace.
Indentation
Each time a new block is opened, the indent increases by one tab character. When the block ends, the indent returns to the previous indent level. The indent level applies to both code and comments throughout the block. Example:
@media screen and (min-width: 768px) {
.selector {
property: value;
}
}
Using indentation is also encouraged in some cases where a value could be a list of tokens. Example:
/* Facilitate reading */
@font-face {
font-family: "Open Sans";
src: url("/fonts/OpenSans-Regular-webfont.woff2") format("woff2"),
url("/fonts/OpenSans-Regular-webfont.woff") format("woff");
}
blockquote {
padding: 20px;
box-shadow: 0 -3em 3em rgba(0, 0, 0, 0.1),
0 0 0 2px rgb(255, 255, 255),
0.3em 0.3em 1em rgba(0, 0, 0, 0.3);
}
.header {
background-image: url("/images/header-1.png"),
url("/images/header-2.png");
}
Declaration
One declaration per line
Each declaration is followed by a line-break.
/* Don't do this */
.selector {
background: #000; font-size: 12px;
}
/* Do this */
.selector {
background: #000;
font-size: 12px;
}
Semicolons are required
Every declaration must be terminated with a semicolon. Even if it’s the last declaration within a selector.
/* Don't do this */
.selector {
background: #000;
font-size: 12px
}
/* Do this */
.selector {
background: #000;
font-size: 12px;
}
Whitespace
Vertical whitespace
A single blank line appears:
- After the
, character that separates between the selectors.
- After the opening braces before the declaration block or other block structures like
@media or @supports.
- After the
; character that terminates a declaration.
- After the closing braces
} after the declaration block or other block structures like @media or @supports.
- Between a declaration and the next one.
- After the
, character that separates between different values for the same property (see the example mentionned earlier in the indentation section).
Example:
/* Don't do this */
.selector-1, .selector-2 {
background: #000;
font-size: 12px;
}
.selector-1,
.selector-2 {
background: #000; font-size: 12px;
}
/* Do this */
.selector-1,
.selector-2 {
background: #000;
font-size: 12px;
}
Exception:
/* If you have a single selector and a single declaration, it's OK to do both of the following */
.selector {
background: #000;
}
.selector { background: #000; }
Horizontal whitespace
Horizontal whitespace is used to separate the different parts of a declaration to facilitate reading. These are the rules to follow:
- Before the openning brace
{ of a declaration block.
- After the
: character that separates the property from the value.
- Between the value and the
!important keyword.
- After the
, character that is used to separate between some values like rgb() color`.
- Between the selector combinators.
Note: in some cases, horizontal white space is required otherwise the whole declaration will be invalid like the spaces between the operands of a calc() function.
.selector-1 > .selector-2 {
font-size: 2rem;
line-height: 2 !important;
background-color: rgba(0, 0, 0, 0.5);
width: calc(100% - 10px);
}
Comments in CSS can only be written in a multi-line format (/* */). Some languages like Sass allow single-line comments (//). We usually don’t need to comment anything in CSS because it’s self descriptive, however, I find it valuable to document any magic numbers we may have.
/* Ambiguous, don't do this */
.selector {
top: 197px;
}
/* Explain what does this value mean */
.selector {
top: 197px; /* Represents the height of the header */
}
/* Even better use custom properties */
:root {
--header-height: 197px;
}
.selector {
top: var(--header-height);
}
If you’re using a preprocessor, note that the // comment doesn’t get compiled into the final output while the /* */ comment is preserved.
Quotes
The quotes we use in CSS are double quotes ".
Language features
Units
Use the unit that’s stuitable for what you’re doing. Examples:
- Percentage unit is stuiable when you define something related to its container.
- Pixel could be suitable when you really need a small value (1px, 2px … etc) instead of using
rem and to avoid some bugs that happen with subpixel rendering.
- In most of the cases
line-height is unitless to let the value be calculated according to the element’s font-size. Other units could lead to undesirable side effects or require modifiation to that value if we change the font-size. The only exception to use a unit is usually when we need to vertically align the text withing a container with a fixed height.
- Do not use any unit when the value is zero except when you define a time value.
- It’s usually a bad idea to use
em for text generated from a WYSIWYG editor.
/* Don't do that */
.selector {
padding: 0px; /* Zero is a unitless value */
line-height: 18px; /* Better use a unitless value to allow the line-height to scale with the font-size changes */
border-width: 0.1rem; /* 1px is enought */
transition-delay: 0; /* This value is invalid as time requires a unit (eg `0s`) */
}
/* The following is a button that appears near the top right of a modal window.
Usually the position of the button isn't related to the dimensions of the
modal so using percentage units here is wrong. It should be replace with
other values like pixels or ems
*/
.close-button {
top: 2%;
right: 1%;
}
Shorthand values
Generally, we prefer to use the shorthand values instead of the expanded ones as long as these values are intended to be set. For example:
/* Don't do this unless you intend to set the vertical margins to zero */
.container {
margin: 0 auto;
}
/* Do this instead */
.container {
/* if you're using post-processors or the intended browsers supports logical properties and values */
margin-inline: auto;
/* or you can do this */
margin-left: auto;
margin-right: auto;
}
Do not override a value with a shorthand value. For example:
a {
padding-left: 10px;
padding: 20px; /* Padding is overriding padding-left making it useless */
}
Do not write redundant shorthand values. For example:
/* Don't do this */
.selector {
padding: 10px 10px 10px 10px; /* `padding: 10px` is enough */
margin: 10px 20px 10px 20px; /* `margin: 10px 20px` is enough */
}
Selectors
Psuedo-classes (:hover, :focus, etc) should use the : prefix, pseudo-elements (::after, ::before, ::selection, etc) should use the :: prefix.
/* Don't do this */
.selector:after {
content: "Whatever";
}
/* Do this */
.selector::after {
content: "Whatever";
}
Try to order your blocks according to the specificity of the selectors from the least to the most specific.
/* Don't do this */
.selector-1 .selector-2 {
color: #000;
}
.selector-1 {
background: #fff;
}
/* Do this */
.selector-1 {
background: #fff;
}
.selector-1 .selector-2 {
color: #000;
}
Do not combine vendor specific selectors with standard ones because it will make the whole declaration invalid.
/* Don't do this, this will not work */
::-webkit-slider-runnable-track,
::-moz-range-track {
background: #fff;
}
/* Do this */
::-webkit-slider-runnable-track {
background: #fff;
}
::-moz-range-track {
background: #fff;
}
These are the important as well:
- Try not to nest more than 3 levels deep.
- Avoid duplicating selectors, it makes it harder to read and maintain.
- Media queries should be defined close to the elements they affect.
- Be careful when you’re using the
:not() pseudo-class because it affect the specificity of the selector. Read more about this here.
Properties and values
Do not write duplicated values for the same property. For example:
/* Don't do this */
.selector {
padding: 20px;
/* ... some styles you write */
padding: 10px;
}
No empty blocks. For example:
/* Don't do this */
.selector {
}
If you’re using an autoprefixer, don’t add a vendor prefix to the property. Autoprefixer will determine if the property is supported by the browsers using browserslist and caniuse. If it’s not, it will add the vendor prefix. For example:
/* Don't do this */
.selector {
-webkit-transition: all 0.5s ease;
transition: all 0.5s ease;
}
In case you have to use a vendor prefix, write the prefixed version of the property before the unprefixed one. For example:
/* Don't do this */
.selector {
transition: all 0.5s ease;
-webkit-transition: all 0.5s ease;
/* Do this instead */
.selector {
-webkit-transition: all 0.5s ease;
transition: all 0.5s ease;
}
Do not use subpixel values. Subpixel values are not supported by all browsers and they can lead to inconsistent dimensions. For example:
/* Don't do this */
.selector {
width: 187.5px;
}
/* Do this instead */
.selector {
width: 188px;
}
Inheritance
Inheritance is one of the most powerful features in CSS. It allows you to reuse styles from a parent selector. It’s preferred to make use of inheritance whenever possible. For example, font-family is inherited from the parent element. If we use a generic selector we explicitly apply the font-family to each element. Applying it to the parent element is a better practice.
/* Don't do this */
* {
font-family: "Helvetica Neue", Helvetica, Arial, sans-serif;
}
/* Do this instead */
body {
font-family: "Helvetica Neue", Helvetica, Arial, sans-serif;
}
Using !important
The keyword !important shouldn’t be used or at best limited to very narrow cases. The only place where you can see !important being used frequently is within the utilities layer. For example:
/* You can do this */
@media (max-width: 767px) {
.hidden-on-mobile {
display: none !important;
}
}
Features specific to CSS
Box Model
In almost all your work you will need to set the box-sizing propert to border-box. This will facilite the calculation of the dimensions of the elements. Some external libraries still use or assume that the box-sizing is set to content-box. To overcome this problem, We set it to border-box on the root element, then inherit it to all the elements. This allows us to override it at any parent and all its siblings whenever we need.
html {
box-sizing: border-box;
}
*, *::before, *::after {
box-sizing: inherit;
}
Fonts
When defining a custom font using the @font-face at-rule, take care of the following:
- Make sure you generate the fonts in the modern formats (
woff2, woff, ttf) and load them in the same order.
- If you’re using different weights for the same font, make sure that:
- The
@font-face at-rules have the same name.
- The
font-weight property is set correctly.
- The
@font-face at-rules are ordered ascendingly according to the weight.
- Use
font-display property and set its value to swap to ensure the users can see the contents soon enough with no flash of invisible text. If the font is used for custom icons, it should be set to block to avoid displaying unreadable text (like square or any odd glyphs).
/* Don't do this */
@font-face {
font-family: "MyFont Light";
src: url("myfont-light.woff2");
}
@font-face {
font-family: "MyFont Regular";
src: url("myfont-regular.woff2");
}
/* Do this */
@font-face {
font-family: "MyFont";
src: url("myfont-light.woff2");
font-weight: 300;
}
@font-face {
font-family: "MyFont";
src: url("myfont-regular.woff2");
font-weight: 400;
}
When you set font, always:
- provide a generic font family name.
- Enclose custom font names within double quotes.
/* Don't do this */
body {
font-family: MyFont;
}
/* Do this */
body {
font-family: "MyFont", sans-serif;
}
Always remember that some elements like input and textarea doesn’t inherit the font family from their parent selectors, hence you should always specify the font family for them (using the inherit keyword or by directly defining the desired font).
Colors
For color values that permit it, 3 character hexadecimal notation is shorter and more succinct.
/* Don't do this */
.selector {
color: #ff0000;
}
/* Do this instead */
.selector {
color: #f00;
}
Do not use keyword color values. Replace it with a hexadecimal notation. For example:
/* Don't do this */
.selector {
color: red;
}
/* Do this instead */
.selector {
color: #f00;
}
Use all lowercase characters in hexadecimal notation. For example:
/* Don't do this */
.selector {
color: #FFE6D8;
}
/* Do this instead */
.selector {
color: #ffe6d8;
}
Floats
In most cases where you want to use float, you should clear the float property using the popular old clearfix hack.
Overflow
Do not use overflow to hide scrollbars if that’s not the desired behavior. Fix the overflow problem by properly making sure the content doesn’t overflow. For example:
/* Don't do this */
body {
overflow-x: hidden;
}
Custom properties / Variables
CSS custom properties are a way to define variables that can be used in CSS. The rules that apply to picking up a good variable name applies to nameing the custom properties (like being representative to the value it holds, not being too generic, etc).
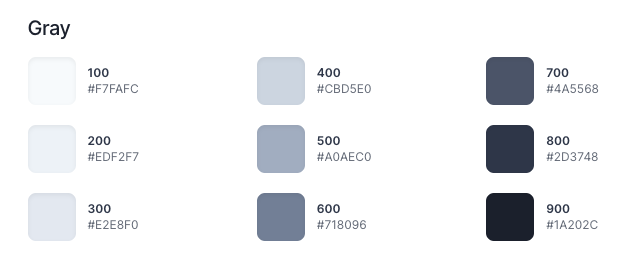
When picking up names for our color variables, we follow the same methodology followed by the Material design and TailwindCSS. For more information about this, read this article.
/* Don't do this */
:root {
--colorPrimary: #2196f3;
--colorSecondary: #9e9e9e;
}
/* Do this instead */
:root {
--red-300: #ff8a8a;
--red-500: #ff4d4d;
}
]]>